Well, the title may be a bit harsh, but at least it grabbed your attention – did it not?!
A week ago, or so, I wrote a wish list to Santa for Denali from a relational developers perspective. In that wish list I wrote that there has been fairly little love for relational SQL developers in the recent versions of SQL Server, and that I hoped in this version (i.e Denali) Microsoft would “go back to the roots” and give us developers some new stuff.
So I downloaded the CTP when it became available, and have been playing around with it for a bit, in order to see what new “stuff” I could find and how it stacked up against my wish list:
Autonomous transactions – not a whiff of it.
Enhancements to SQLCLR – Denali is still loading version 2.0.50727 of the runtime (i.e. the original “SQL 2005” version). So nothing here either, and they have not even added Microsoft.SqlServer.Types (for the geo and hierarchy types) to the blessed list. This (lack of SQLCLR enhancements) is probably the one thing that saddens me the most – it seems that after all the initial hoopla and fanfare about SQLCLR when it was introduced in SQL Server 2005, Microsoft has decided to not fullfil its potentials.
Finally blocks – well, we do not have finally blocks but we now have a proper way of throwing and re-throwing exceptions; the THROW keyword. I wrote about it here and here. So at least this is something.
Other T-SQL enhancements – this is an area where there are at least a couple of new things: SEQUENCE and OFFSET. Those are cool and useful and Aaron B wrote about them here and here. But this is still not very much, and no evidence of that Microsoft want to continue to enhance T-SQL as a first class development language (as they have stated in the past).
So, the report card does not look that good and that’s the reason for the title of this post. Granted, there are things that are in the cards but not included in this CTP; things like:
Column storage – however, that is more a BI feature, but it will be usable in the OLTP world as well.
FileTable – a way of storing files in SQL Server. It looks like FileStream v.NEXT or (do I dare say it) WinFS (now I have most certainly condemned this to death). It looks interesting, but – as I said – not in this CTP.
As you can gather from the above, I am not that stoked about Denali. I hope later CTP’s will bring more things, but somehow I doubt it.
What are your take on this, are you happy with what Denali gives you (from a relational developers perspective), and if not – what would you like to see included. Answers in the comments please.
Recently I have become very interested in F# and I am at the moment trying to get to grips with it. It is definitely a different beast than C#, but so far I like it – a lot!
Anyway, I am a SQL nerd, and many moons ago I was very heavily involved in SQLCLR (for you who don’t know what that is; it is the ability to run .NET code inside the SQL Server engine. It was first introduced with SQL Server 2005). So I thought it would be a “giggle” to see if I could get some F# code running inside SQL Server.
I created the simplest of the simple F# dll’s. SQLCLR requires you have a public class and your publicly exposed SQLCLR methods to be static, so my F# code looked like so:
As you can see my class is extremely advanced (not); it has two methods:
The canonical Adder method (every SQLCLR dll has to have an Adder method, it’s the law – nah, I’m just kidding), which takes two integers and returns an integer.
A factorial method, which takes an integer and calculates the factorial from that.
By the way, any pointers about how to write efficient F# code are very welcome .
Having written and compiled the code, it was time to deploy! When running .NET code in SQL Server, you need to deploy your assembly to the database you want to execute your code in, and SQL Server will actually load the assembly from the database. In fact most assemblies are loaded from the database, even quite a few of Microsoft’s own system assemblies which normally are loaded from the GAC. There are only about 13 system assemblies that are allowed to be loaded from the GAC these are known as the “blessed list”. You also need to create T-SQL wrapper objects (procedures, functions, triggers, etc.) around the methods you want to publicly expose.
In my SQL Server 2008R2 instance I created a database in which I wanted my F# assembly to, and then it was time to deploy. You can deploy in several ways, the easiest is something like this (in the database you want to use):
The problem with the code above is that F# projects have a dependency on the assembly FSharp.Core.dll, so when I tried to deploy my assembly as per above, I got an exception. What I had to do was to deploy FSharp.Core.dll to my database first:
1234
CREATEASSEMBLYfsasmFROM'C:\path to ...\FSharp.Core.dll'WITHpermission_set=UNSAFE;GO
Notice the use of permission_set = UNSAFE, this is to tell SQL Server that I know what I am doing and SQL Server should keep from doing a lot if validation. When I had catalogued the FSharp.Core.dll assembly I had no problems deploying my assembly to the database.
All there remained to do now was to create the T-SQL wrapper object(s) around my F# methods. This is done with “normal” CREATE ... syntax. The code for my factorial looks like so:
This also went without problems, so now it is “crunch-time”. Can I execute a F# method in SQLCLR?
1
SELECTdbo.FsFactorial(4);
Lo and behold, it executed and I received 24 back! I had just now executed F# running inside SQL Server!!
So, what does this prove? Nothing really, it was just an exercise from me to see if it could be done. However, F# is really suitable for quite a few tasks you would want to use SQLCLR for, so it now gives a database developer another tool in his tool-belt.
If anyone is interested in the full code for this, please drop me a comment and I’ll email it to you.
At PDC 2010 Microsoft showed the new Async features of coming C# (and VB.NET) versions, and quite a lot has been written about it already. Part of the Async CTP is TPL Dataflow, and this has gone somewhat un-noticed.
TPL Dataflow is a library for building concurrent applications. It utilises an actor/agent-oriented designs via primitives for in-process message passing, dataflow, and pipelining. It looks and feels a bit like Axum, and one can wonder if TPL Dataflow will be the productization (is this a word?) of Axum, especially as Axum’s future seems a bit unclear at the moment.
I am at the moment writing some test-code for TPL Dataflow, which I will post as soon as I have tidied it up a bit. In the meantime Matt Davey, has quite a few posts about TPL Dataflow on his blog. So if you are interested, go and have a look.
This is a first post about my experiences with running F# and Mono on a Mac.
In a previous post I wrote about how I have started to play with F#. As that post also covered SQLCLR it was obvious I was on Windows. Even though I make my living from development in a Windows environment, my main machine is a MacBook, and I run OSX as my main OS. I have previously also been running Linux (ArchLinux) on this machine as my main OS. Naturally I have heard about Mono (and also installed it a couple of times – and quickly un-installed again, but I have not really done anything with it. I have always run Windows in a VM on my MacBook for development etc. However after the announcement that F# was going Open Source, and Tomas Pposted about his F# MonoDevelop plug-in, I decided that I should have a look at what it would be like to do F# “stuff in OSX.
Having downloaded what I thought was necessary (I decided to hold off with MonoDevelop until I had everything running), I started the installation process. Installing Mono was straight forward, just mount the .dmg and then run the .pkg file. The only slight issue after installation was where it had been installed. Mostly for my own reference for later installations; Mono is located at: /Library/Frameworks/Mono.framework.
After I had installed Mono, I copied the bin directory from the unzipped F# file to a directory I created in the same root folder as where Mono was: /Library/Frameworks/FSharp. I copied the install-mono.sh file to the FSharp directory and was ready to start the installation. Fortunately before I executed the install-mono.sh file, I read the comments in the file. At this stage I realised I had not downloaded everything necessary.
One of the F# dll’s FSharp.Core.dll needs to be installed in the gac. In order to do that, the dll needs to be re-signed with the mono.snk key. The installation file mentions how you can download the file using wget. As I did not have wget I found a link to it and downloaded it by right-clicking on the link and choose “Save Link As”. Once again mostly for my future reference; the file can be found here, (just right click and choose “Save Link As”). I saved it into the F# root folder (the same folder where the install-mono.sh is).
So, now everything should be ready to go. I executed the install file and promptly got an error saying that the FSharp.Core.dll could not be installed in the gac. Hmm, not good! Fortunately the error message mentioned something about a possible permission error, so I looked at the permissions on the gac folder (../Mono.framework/Versions/2.8/lib/mono/gac), and sure enough – I did not have write permissions. I gave myself write permissions, and re-ran the installation and everything went OK. Cool!!
After this it was time to test it out. From the F# bin directory I ran the following from a terminal window to execute the compiler: mono fsc.exe. It seemed to work as I got this error back:
I then tried the interactive window: mono fsi.exe. I wrote some simple test code:
As you can see, that worked as well!! So I am now well on the way of running (and learning) F# on Mono. Next step is to install MonoDevelop and Tomas P’s plugin for F#. Stay tuned…
So yesterday I wrote about how I have started using F# and Mono on my MacBook.
I wrote about how I downloaded the F# bits, unzipped and put them in a specific directory I had created. Today after having browsed around a bit more I realized I had done it the hard way. To install the required bits for F# for Mac, you only have to download a zip file with an install package for Mac from the F# Cross Platform site on CodePlex. The actual zip-file for the November 2010 CTP is here.
After you have downloaded the file you unzip it and run the .pkg file. This takes care of everything; no re-signing with the .snk file etc. The added benefit of installing from the .pkg file is that a couple of F# compiler dll’s are automatically gac:ed (they are needed if you want to run the F# plugin for MonoDevelop), and aliases are created for the F# compiler and the F# interactive window.
Transactions in SQL Server seems to be a difficult topic to grasp. This weekend I came across a blog-post where the poster showed a “solution” to the “The ROLLBACK TRANSACTION request has no corresponding BEGIN TRANSACTION” error we sometimes see when various stored procedures call each other. The solution (even though it masked out the error in question) did not get it quite right. So I thought I would make a post about the subject.
Nested Transactions in SQL Server and the Evil @@TRANCOUNT
In SQL Server we have the @@TRANCOUNT variable which gives us the number of transactions active in the session – or that’s at least what we might believe. Take this extremely simple code:
I.e. it seems like the transaction count is increasing for each BEGIN TRAN, and decrease with COMMIT. And if you were to SELECT * FROM #t you would see two rows returned. So far so good, so what is wrong with @@TRANCOUNT then? Well, let us change the code slightly (don’t forget to drop #t if you copy and paste this code):
If you now were to (don’t do it immediately) SELECT * FROM #t, how many rows would you get back – 0, 1, or 2? Seeing how the @@TRANCOUNT is increasing with every BEGIN TRAN and decreasing with COMMIT / ROLLBACK, it is understandable if your answer is 1:
we start a transaction and insert a row
we then start another transaction and insert a second row
we call commit after the second insert (the inner transaction)
finally we do a rollback, on the “outer” transaction
As we after the second BEGIN TRAN can see @@TRANCOUNT being 2, we could assume that the commit would commit the second insert. However, we all know what happens when we assume (now would be a good time to do the SELECT) ….
Right, the SELECT did not return any rows at all, so it is probably fair to say that we did not have multiple transactions, even though @@TRANCOUNT showed us more than one. So, then we might assume (keep in mind what I’ve said about assume) that the reason we rolled back was because ROLLBACK was the last statement. Let us switch the COMMIT on line 10 with the ROLLBACK on line 12 (we now have ROLLBACK on line 10 and COMMIT on line 12) and execute. WHOA – we got a big fat exception, what happened here? To answer that, let us look a bit closer at the main parts of transaction control in your code.
BEGIN TRAN, COMMIT and ROLLBACK
When you execute BEGIN TRAN in T-SQL, SQL will look around in the execution context of your session and see if there already exists a transactional context. If not, SQL will start a new transaction. If there is a transaction already, SQL will enlist in this transaction. However in both cases SQL will increase the @@TRANCOUNT variable.
Then, when you execute a COMMIT, SQL will not immediately commit the transaction but will decrease the transaction count with 1. If the transaction count has reached 0 due to the commit, a commit will take place. OK, so far so good, but this does not explain the error we received when switching the COMMIT and ROLLBACK statements, if it works as described, then we should have committed?
Ah, yes – however, a ROLLBACK not only decrements the transaction count – it sets it to 0 immediately, and as the transaction count is now 0, a rollback will happen. So in our second example we are seeing something similar to when we – in stored procs – are getting the ”The ROLLBACK TRANSACTION request has no corresponding BEGIN TRANSACTION” error.
Stored Procedures and Transactions
It is quite common to write procs something like so:
12345678910111213141516
CREATEPROCsp2ASSETNOCOUNTONBEGINTRANBEGINTRY-- do some stuff-- then if all is OK we commitCOMMITTRANRETURN0;ENDTRYBEGINCATCHDECLARE@errMSgvarchar(max);SELECT@errMSg=ERROR_MESSAGE()ROLLBACKTRANRETURN999;--things have gone very wrongENDCATCH
Then we are having a similar proc, looking almost the same, but it, in addition, calls into sp2:
123456789101112131415161718
CREATEPROCsp1ASSETNOCOUNTONBEGINTRANBEGINTRY-- do some stuff-- do some more stuff by calling into sp2EXECsp2;-- then if all is OK we commitCOMMITTRANRETURN0;ENDTRYBEGINCATCHDECLARE@errMSgvarchar(max);SELECT@errMSg=ERROR_MESSAGE()ROLLBACKTRANRETURN999;--things have gone very wrongENDCATCH
This is now when we will potentially see the error mentioned before. We call sp1, when sp1 is called there is no transactional context around, so SQL creates a new transaction. Then we go on to call sp2 from sp1. In the BEGIN TRAN call in sp2, there exists a transactional context, so SQL enlists us in that context.
If all now goes well and we call COMMIT in sp2, the commit causes the transaction count to be decreased to 1 – but no “real” commit happens. So when we subsequently calls COMMIT in sp1, we decrement the transaction count to 0, and we are committed.
In the case when things go wrong is sp2 and we call rollback, the transaction count is immediately set to 0, and a rollback happens. When we come back to sp1, SQL sees that we had a transaction in sp1, but there are no transactions around, and we will get the error discussed. If we then go on and do a rollback (as in our code) – we will get additional errors.
Solution
A solution to the problem is to use the “evil” @@TRANCOUNT, to see if there are any transactions around. If there aren’t any, we start a transaction. If there are a transaction already, we don’t do anything, and we let the existing transaction handle everything:
12345678910111213141516171819202122232425262728
CREATEPROCsp2ASDECLARE@tranCountint=@@TRANCOUNT;--I'm using SQL2008 hereSETNOCOUNTONIF(@tranCount=0)--no tx's around, we can start a newBEGINTRANBEGINTRY-- do some stuff-- then if all is OK we commit--if the variable @tranCount is 0,-- we have started the tx ourselves, and can commitIF(@tranCount=0ANDXACT_STATE()=1)--XACT_STATE - just to be on the safe sideCOMMITTRAN;RETURN0;ENDTRYBEGINCATCHDECLARE@errMSgvarchar(max);SELECT@errMSg=ERROR_MESSAGE()--if the variable @tranCount is 0,-- we have started the tx ourselves, and can rollbackIF(@tranCount=0ANDXACT_STATE()<>0)--XACT_STATE - just to be on the safe sideROLLBACKTRAN;--tell an eventual calling proc that things have gone wrong--and the calling proc should rollbackRETURN999;ENDCATCH
Obviously the calling proc would have similar code to decide if to start a tran or not.
In the above scenario we let the “outer” proc handle all the transactional control. Sometimes you are in a situation where – if things go wrong in the “inner” proc (sp2 in our case) – you do not want to roll back everything done, but only what was done in the inner proc. For such a scenarion, you can use named savepoints:
CREATEPROCsp2ASDECLARE@tranCountint=@@TRANCOUNT;--I'm using SQL2008 hereSETNOCOUNTONIF(@tranCount=0)--no tx's around, we can start a newBEGINTRANELSE--we are already in a tx, take a savepoint hereSAVETRANSACTIONsp2--this is just a nameBEGINTRY-- do some stuff-- then if all is OK we commit--if the variable @tranCount is 0,-- we have started the tx ourselves, and can commitIF(@tranCount=0ANDXACT_STATE()=1)--XACT_STATE - just to be on the safe sideCOMMITTRAN;RETURN0;ENDTRYBEGINCATCHDECLARE@errMSgvarchar(max);SELECT@errMSg=ERROR_MESSAGE()--if the variable @tranCount is 0,-- we have started the tx ourselves, and can rollbackIF(@tranCount=0ANDXACT_STATE()!=0)--XACT_STATE - just to be on the safe sideROLLBACKTRAN;ELSEIF(@tranCount>0ANDXACT_STATE!=-1)ROLLBACKTRANSACTIONsp2--we are rolling back to the save-point--tell an eventual calling proc that things have gone wrong--and let the calling proc decide what to do with its partsRETURN999;ENDCATCH
Personally, I do not use named save-points that much as they cannot be used together with linked servers, and we – unfortunately – are using linked servers a lot.
A final note about named save-points; they are not the same thing as beginning / committing / rolling back a transaction with a name:
Beginning a transaction with a name, is for most parts just a convenience. It has no effect on nesting (unless you use named save points), and SQL Server Books OnLine says this about naming of transactions: “Naming multiple transactions in a series of nested transactions with a transaction name has little effect on the transaction. Only the first (outermost) transaction name is registered with the system. A rollback to any other name (other than a valid savepoint name) generates an error. None of the statements executed before the rollback is, in fact, rolled back at the time this error occurs. The statements are rolled back only when the outer transaction is rolled back”.
If you have questions, observations etc., please feel free to leave me a comment, or drop me an email.
I have a while ago just finished watching the live stream of the first keynote (yes there will be one tomorrow as well), at Microsoft BUILD. Having attended / presented, at quite a few of these kind of events – and being somewhat jaded (well OK then, a lot jaded), I must still say that I am impressed.
As quite a few other developers I have been fairly worried about what will happen when Win 8 comes; .NET/WPF/SilverLight is dead – long live HTML etc., but at least for now it seems that the fears have been un-founded. I.e, the .NET as we know and love is still there, SilverLight as well (come to think about it, nothing much was said about WPF). And it seems pretty straightforward to build the new “Metro” style apps using the tools we know.
What do I think then: well, Win 8 promises to be really, really slick and cool – but we have been here before (Longhorn anyone?), so let’s wait and see until we get to RC stages. However, the whole Win RT, i.e the underlying “goo” of Windows (graphics, networking, etc) being exposed to all different types of programming languages; native, .NET, HTML/JavaScript, etc., seems very, very cool. I can’t wait to get my hands on some bits and start playing around with this. Speaking of that; bits will apparently be released later.
So at this stage I am fairly optimistic, and I would not rule out, myself running Win 8 on a couple of machines here at home. I am looking forward to the keynote tomorrow, where they will talk more about the development experience, and hopefully drill deeper into Visual Studio.Next.
Having finally seen the session-list, there are some really interesting sessions during the week. I really, really hope these ones will be videoed:
As some of you may know, I – once upon a time – developed a project (VS add-in, templates, etc) for automatic deployment of CLR assemblies to SQL Server: SqlClrProject. That project has been dormant now for a couple of years, but I now and then get requests for where it can be downloaded from (I had it on CodePlex, but had to take it down as I didn’t publish the source code).
A while ago I decided to start to use Git and GitHub as source control (I have been using SVN since forever), and as part of the “getting to grips” with Git, I created a repo for SqlClrProject on GitHub. So the source for the project is now available on GitHub.
If you are interested in the fork it, play with it. The state of it is that it “should” work on VS 2008 / SQL 2008. It most likely will work on VS 2010 as well. And of course the standalone deployment executable will work regardless of VS version.
Every so often I get an itch, and I want to try out a new blog-platform. The time has now come to leave my self-hosted WordPress and move on to something “geekier” (I am a geek after all).
I have just now finished moving my few posts from WordPress to the new engine: OctoPress. In a future blog post on the new blog I will try to explain why I made the move, and why OctoPress. The new blog will be hosted on Windows Azure– I do get free Azure credits together with my MSDN subscription, so I thought I’d see what all the “fuss” about Windows Azure is.
As of a couple of minutes ago, I pointed a CNAME record for www.nielsberglund.com to my new Windows Azure host. We’ll see after a while if all worked. RSS feeds etc. should be as before – as I use feed-burner.
In an earlier post, I wrote how I had changed blog-engine from WordPress to OctoPress. At the moment I am running Windows as my main OS (mostly due to work related requirements), and – as OctoPress is very much Ruby and Python based – there are certain things to be aware of when installing this on Windows. Furthermore, my blog is now hosted on Windows Azure– so, with all this in mind, I thought I’d put together a blog post about the set-up of OctoPress on Windows, running on Windows Azure.
Pre-Reqs
Before you begin the installation there are some pre-req’s:
Git and GitHub
Octopress is a developers blog engine, and central to everything Octopress is Git. Make sure you have the latest version of Git for Windows installed. You also need a GitHub account, so if you don’t have a GitHub account, you should sign up for one. While you probably will do most of the Octopress Git and GitHub related tasks from command-line, it will not hurt to have the GitHub for Windows UI application installed as well.
Ruby
Octopress is built on Ruby, and when you eventually create blog-posts you will execute Ruby commands, so you need to install Ruby and the Ruby Development Kit. Octopress seems somewhat “picky” about what Ruby version to use, personally I am running version 1.9.3-p448, and it works fine.
You also need to install the Ruby Development Kit (DevKit) so you can use some of the native C/C++ extensions. Which version to download is dependent on the Ruby version, but I am running 4.5.2, DevKit-tdm-32-4.5.2-20111229-1559-sfx.exe.
After you have downloaded and installed both Ruby as well as the DevKit, you need to run two installation scripts for the DevKit:
change to the directory where the devkit is installed, and run: ruby dk.rb init.
then – still in the same directory – run ruby dk.rb install.
For more information about the installation of Ruby and the DevKit, GitHub has a great wiki page.
Python
In addition to Ruby you need Python (this mostly for syntax highlighting). When installing Python, the version is very important. Download and install Python 2.7 from here.
Having installed all the above you should now be set for the actual installation of Octopress!!
Install Octopress
To install Octopress you need to clone the “original” Octopress repo from GitHub. From command-line you cd to the directory where you want clone the Octopress repo into, alternatively you create a directory for this and cd into it.
In the code below the assumption is that the directory exists and it is named MyGitHubRepos. As you can see from the code, after you have changed into that directory you clone the original Octopress directory into a new directory with a name of your choice. In the example below, the name is myoctopressblog.
12
$ cd MyGitHubRepos$ git clone git://github.com/imathis/octopress.git myoctopressblog
After having cloned the original GitHub repo, you need to install a Ruby bundler. The Bundler maintains a consistent environment for Ruby applications, and you install it into the directory you cloned Octopress into (in the case above: myoctopressblog). BTW, gem is like a package installer:
123
$ cd .\myoctopressblog$ gem install bundler$ bundle install
By now your blog is almost 100% complete. What remains is an Octopress theme. For the initial setup, the default theme will do. To install this you run the equivalent of a MAKE file, a rake file:
1
$ rake install
Congratulations you now have an Octopress blog!! If you are curious what it looks like you can now run rake commands to generate and preview the blog pages:
12
$ rake generate$ rake preview
After you have executed the rake preview command you can browse to localhost:4000 and see the blog in all its glory. If you did browse to localhost:4000, you can see that you have a very basic blog. By now you definitely want to configure the blog, and maybe also write – at least – a Hello World post.
Configuring Octopress and writing an initial post
The official Octopress site has very good documentation about all things Octopress. So, instead of me re-iterating everything about configuration and using Octopress for blogging, I rather point to the official documentation for configuration and basics about blogging with Octopress.
Right, by now you should have fairly good idea how to use Octopress – it’s awesome, right?! But … hang on a second, we are missing something – right; as awesome it is, the blog is still only on your local machine. So what do we do if we want to host the blog somewhere out on the interwebz?
Deploying Octopress
In order to get a fully functional blog, we need to host it somewhere, and with Octopress there are some nice and easy ways to deploy and host the blog. As with the secion about configuring the blog, I’ll let the official documentation do the talking for some of the ways Octopress can be deployed:
In order to publish posts to all of the options above you need to run rake generate followed by rake deploy after having written a post(s).
I mentioned up at the top how I was hosting this blog on Windows Azure, how is that done?
Hosting Octopress on Windows Azure
I initially thought I would host the blog on GitHub pages, and I did set up the blog to be deployed to my GitHub pages. Then, somehow, I thought that maybe I should check out Windows Azure – seeing that I have – through my work at Derivco– an MSDN subscription (Derivco rocks!), and the subscription gives me Windows Azure credits.
So, on to the wisdom of all world (Google), and lo and behold – there were quite a few posts / articles how to link a blog to Windows Azure. Seeing that I already published / deployed to GitHub pages it was extremely easy to push this to Windows Azure:
Set up a web-site through the Windows Azure portal
Configure the deployments to point to the GitHub pages
That’s all there is to it. Now after you have run rake generate and rake deploy, when you commit, the changes will be published to Windows Azure:
123
$ git add .$ git commit -m "Some message about the commit"$ git push origin source
Oh, I almost forgot – I also needed to point a CNAME for my domain to my website on Windows Azure. But, the whole Windows Azure setup took less than 10 minutes!!
The two first weekends in August I were in Cape Town and Johannesburg respectively presenting at SQL Saturday events. I had a great time, and the audience were terrific. My employer Derivco graciously gave me some “swag” to hand out, and that went down a treat. Thanks Derivco!!
After the events some people have emailed me and asked for the presentations, so I thought I’d upload them to SlideShare, so anyone that are interested can get to them. Seeing that I recently switched to a new blog platform, Octopress, and I a couple of days ago came across a SlideShare plugin for Octopress – I decided to test it out by posting the presentations here on my blog.
The two presentations I did were based about the “weird/wonderful (or not so wonderful)” things we have experienced at Derivco in our live production environments:
SQL Real World Error Handling– Gotcha’s when doing error-handling in SQL Server
Message Queues in SQL Server– Enhance performance by using queues in SQL Server
SQL Real World Error Handling
This presentation talks about strange scenarios that can catch unaware developers out when mixing the new way of handling errors instroduced in SQL Server 2005, with what we used to do before:
New Style SQL Server Error Handling
123456
BEGINTRY-- do some stuff that may cause an errorENDTRYBEGINCATCH--handle error, and perhaps re-raiseENDCATCH
One of the first thing I usually do after having installed a new version of SQL Server is to snoop around at the system tables to see what new tables there are and what they can give me information about.
As you may know by now, in SQL Server 2005 the system tables are not longer visible. The information from the system tables are instead exposed as Dynamic Management Views (DMV). These DMV's gives you a lot of information about the state of your SQL Server, the problem is how to interpret the views and what views to look at when you try to solve a specific problem.
Fortunately Slava Ok from Microsoft is planning to post a series of blog entries about DMV's where he emphasizes on what actual problems the DMV's can be used to solve. The first installment is now up, and you can find it here. Happy reading!!
What can I say, I am crap at this "blogging" thing! Three years ago, I resuscitated my blog, after a hiatus of one year. I also switched blog engine from WordPress to OctoPress (which at that stage was version 2). At the time of the switch, I had had a one year hiatus of blogging (I am not a very prolific blog writer :)), and I remember I was very tempted to write in that post, that if I cannot keep up blogging I will quit. Boy, am I glad I did not write that!
So here we are, three years later (what are a couple of months between friends), and I am about to write blog posts again. This time I have not switched blog engine - but I have upgraded from Octopress 2 to 3.0. So why am I doing this? The easiest answer to that would be that "I have no effing idea why, other than that I must be a masochist", however there are a couple of other reasons:
Slava Oks - for you young "whipper snappers" out there; he was Mr. SQLOS and Mr. SQLCLR back in the day of SQL Server 2005 - what he didn't know about SQLOS was not / is not worth knowing. He has recently come back after a 10 year blogging hiatus, so if he can ...
I still like "putting pen to paper", and write about things I enjoy.
Right, so that's it! Let us see what happens going forward!
Way back when (in 2010 as a matter of fact), I wrote a couple of blog-posts (here and here) about error handling in the new CTP releases of SQL Server Denali. Denali was what would become SQL Server 2012.
The new functionality built upon what was introduced in SQL Server 2005 - the notion of structured exception handling through BEGIN TRY END TRY followed by BEGIN CATCH END CATCH. In those blog-posts I was fairly positive, and saw the new functionality as something useful and very well worth implementing. I am still positive, however since then I have used the new functionality introduced in SQL Server 2005 extensively in production and have come across some gotchas that I thought would be worth writing a blog-post about.
Background
Before SQL Server 2005 was introduced, and with that structured exception handling as mentioned above, the way we handled error conditions in SQL Server was to write something like so:
SQL Server Error Handling Pre SQL Server 2005
-- do something where you need to check error condition
INSERTINTOdbo.tb_SomeTable--something may go wrong here
VALUES(....)
SET@err=@@ERROR-- @err has been declared previously
IF(@err<>0)
BEGIN
-- code to handle the error, cleanup, etc.
...
-- re-raise to let calling procs know something has gone wrong
RAISERROR('Some descriptive message',16,-1)
RETURN
END
Code Snippet 1:Old Style Error Handling
In your stored procedures, you had to insert code like above after each statement where you wanted to check for errors. Part of the error-handling code quite often would be some logging/auditing and general rewind/cleanup. Typically you would also re-raise the error so that calling procs would be made aware that something has happened, and in the calling procs you would have similar logic to catch the errors being raised.
All in all, quite a lot of code to write. At Derivco we have a lot of stored procedures, and they can be fairly big (3000 - 4000 loc), so you can imagine the number of error checks we have in them.
TRY CATCH
Writing the above mentioned error-handling code feels quite arcane if you compare what you would do in other programming languages. So in SQL Server 2005 Microsoft introduced the notion of structured exception handling as I mentioned above, and it was implemented through BEGIN TRY ... END TRY and BEGIN CATCH ... END CATCH blocks. As with other programming languages you can have one or more TRY ... CATCH blocks, and when an error happens inside the TRY block, the code in the CATCH block is immediately hit.
SQL Server 2005 TRY CATCH
BEGINTRY
--lots and lots of code
...
...
INSERTINTOdbo.tb_SomeTable--something may go wrong here
VALUES(....)
--more code
...
-- we indicate all is good
RETURN0
ENDTRY
BEGINCATCH
-- code to handle the error, cleanup, etc.
...
-- re-raise to let calling procs know something has gone wrong
RAISERROR('Some descriptive message',16,-1)
RETURN
ENDCATCH
Code Snippet 2:Error Handling with TRY ... CATCH
When the BEGIN TRY ... END TRY block together with BEGIN CATCH ... END CATCH executes, it creates a special error context, so that any errors happening will be caught by the closest CATCH block. In other words, errors "bubble" up to the closest CATCH block, within the same SPID. Keep this in mind, as it is important when we discuss some of the "gotcha's".
THROW
Ad good as the new error-handling functionality was in SQL Server 2005, there were still some pieces missing when comparing t-sql with other languages error-handling. One big glaring missing piece was how to re-throw a caught exception. What you typically would do if you wanted to re-throw was to capture the error text, either from sys.messages pre SQL Server 2005, or from ERROR_MESSAGE() in SQL SERVER 2005+, and in both cases then use the captured text in RAISERROR.
Note about RAISERROR:
It allows you to throw an error based on either an error number or a message, and you can define the severity level and state of that error.
If you call RAISERROR with an error number, that error number has to exist in sys.messages.
You can use error numbers between 13001 and 2147483647 (it cannot be 50000) with RAISERROR.
RAISERROR has been around "forever", and for SQL Server 2012 Microsoft introduced THROW as new function to be used when raising exceptions. Some of the features of THROW:
THROW can be used to re-throw an exception.
Using THROW you can throw a specific error number together with an accompanying message.
Code snippet 3 below shows an example of this:
TRY CATCH with THROW
BEGINTRY
--some code
--here we are doing a check of something
--and realizes that something is wrong
THROW50001,'Ooops',1;
--we will never get here
RETURN0
ENDTRY
BEGINCATCH
-- code to handle the error, cleanup, etc.
...
-- re-raise by using THROW
THROW
RETURN
ENDCATCH
Code Snippet 3:Error Handling with THROW and TRY ... CATCH
If you have managed to stay awake until now, you probably wonder where is the problem with all this, this looks pretty sweet, or as we use to say in the team I work for in Derivco; "What could possibly go wrong?"! Whenever we say that, it seems that quite a few things can go wrong :) and the same thing holds true here, as we will see!
The Problem
The problem comes in when you are mixing "old" (pre 2005), with "new" (2005+) error handling. You may ask: "why would you ever want to do that, why not use only the new cool features?". In fact that's what I asked when I visited Derivco back in 2009 and taught a Developmentor SQL Server course for the team I eventually would work for. Boy was that a stupid question!
The answer - in Derivco's' case - is complexity. In our main OLTP production database we now have ~5,000 stored procedures, and the call stacks can nest 10 - 15 procedures deep. In addition, our procedures are not simple CRUD, but we do have LOADS of business logic in them. So you cherry-pick what procs to edit, most likely some you are changing anyway, and all new procs are written using the new error-handling. What could possibly go wrong with this approach?!
Well, chances are that the new/edited procs are part of a call chain, and not necessarily the last proc in the chain. This is now the situation where issues can happen. Let's look at this a bit closer. In the demo code for this post, we have initially four procedures:
dbo.pr_Caller which calls into
dbo.pr_1 which calls into
dbo.pr_2 which calls into
dbo.pr_3 which is the last proc in the chain.
The three first procs pr_Caller, pr_1 and pr_2 looks almost identical, and I let dbo.pr_Caller be the "showcase":
Example of the Three First Procs
CREATEPROCdbo.pr_Caller
AS
SETNOCOUNTON;
DECLARE@errint;
--do some stuff
--then call into dbo.pr_1
PRINT'dbo.pr_Caller: We are now about to execute dbo.pr_1'
EXECdbo.pr_1
SELECT@err=@@ERROR;
IF(@err<>0)
BEGIN
--clean up and log etc.
PRINT'dbo.pr_Caller: We are cleaning up, rewinding, blah, blah'
RAISERROR('dbo.pr_Caller: Something went wrong when calling dbo.pr_1',16,-1)
RETURN
END
GO--end dbo.pr_Caller
Code Snippet 4:Example of Calling Proc
The last proc in the chain - dbo.pr_3 - is somewhat different in that it generates an error:
The Proc that Generates the Error
CREATEPROCdbo.pr_3
AS
SETNOCOUNTON;
DECLARE@errint;
PRINT'dbo.pr_3: We are now about to do a division 0 error'
SELECT1/0;
SELECT@err=@@ERROR;
IF(@err<>0)
BEGIN
--clean up and log etc.
PRINT'dbo.pr_3: We are cleaning up, rewinding, blah, blah'
RAISERROR('dbo.pr_3: Something went wrong in dbo.pr_3',16,-1)
RETURN
END
GO--end dbo.pr_3
Code Snippet 5:Error Proc
When you look at the procs you can see that they all use the old style error handling, and are doing clean-ups etc in the IF(@err <> 0) block. If you execute the calling proc: EXEC dbo.pr_Caller, the result in the Message tab in SQL Server Management Studio (SSMS) would look something like:
Figure 1:Output from Error Procs
From the figure above we can see:
we are calling into each proc: We are now about to execute.
the division by 0 error happens: Divide by zero error encountered.
each proc in the call chain cleaning up, etc.: We are cleaning up ....
This is good (well not good that we are getting an error), but we are handling it and cleaning up after ourselves. We may perhaps write the errors to some logging tables, so that we in case of un-expected behavior can trace and see what has happened.
Let us now assume that we need to change dbo.pr_1, to add some new functionality, whatever. This is now a good time to alter this old proc to use the new "cool" error-handling:
New Error Handling in dbo_pr1
CREATEPROCdbo.pr_1
AS
SETNOCOUNTON;
DECLARE@errint;
--add the new "cool" errorhandling
BEGINTRY
--do some stuff
--do some other stuff
--then call into dbo.pr_2
PRINT'dbo.pr_1: We are now about to execute dbo.pr_2'
EXECdbo.pr_2
ENDTRY
BEGINCATCH
--clean up and log etc.
PRINT'dbo.pr_1: We are cleaning up, rewinding, blah, blah'
RAISERROR('dbo.pr_1: Something went wrong when calling dbo.pr_2',16,-1)
ENDCATCH
GO--end dbo.pr_1
Code Snippet 6:Edited Proc
No problem with the changes, however when you execute you get following result:
Figure 2:Output from Altered Error Procs
Where is the cleanup in dbo.pr_2 and dbo.pr_3, as an error clearly has happened as something was caught in dbo.pr_1? Oh, and what happened with the error-handling in dbo.pr_Caller, we did raise an error in dbo.pr_1?
The last question is the easiest to answer, and fix; if you want old style error-handling to be able to catch an error raised from within a CATCH block, the RAISERRORMUST be followed by a RETURN, and it has to be a RETURN with no variables! So change the CATCH block in dbo.pr_1 to:
Edited Catch Block
...
BEGINCATCH
--clean up and log etc.
PRINT'dbo.pr_1: We are cleaning up, rewinding, blah, blah'
RAISERROR('dbo.pr_1: Something went wrong when calling dbo.pr_2',16,-1)
RETURN-- this will ensure the old-style error handling will be able
-- to catch the raised exception
ENDCATCH
GO--end dbo.pr_1
Code Snippet 7:Use RETURN After Raising an Exception
If you after the above change were to EXEC dbo.pr_Caller you would see how pr_Caller would handle the error raised in pr_1 as well. The first issue which arguably is more severe is easy to answer; it has to do with that "error context" mentioned in the beginning.
Error Context (a.k.a "Go Straight to CATCH Without Passing IF(@@ERROR")
As I mentioned in the beginning, when a stored procedure is executed, and during the execution it comes across BEGIN TRY block(s), a special execution context(s) is created from the point of the first BEGIN TRY . This context "wraps" all code from that point on, and ensures that if an error happens, the execution will stop and the closest BEGIN CATCH block will be hit. That is the reason why the cleanup code in neither dbo.pr_3 nor dbo.pr_2 was executed.
The answer was easy, but the fix is neither easy nor straightforward. The only way (I am aware of) is that if you edit/create a new proc using the new way of handling errors, you need to ensure that the whole call-stack from that way onward is also using the new way.
THROW
Finally (pun intended), let's discuss THROW, as so far we have not seen any traces of it in the code. Let us edit dbo.pr_3 to use new error handling as well as using THROW to re-throw an exception:
Using THROW in dbo.pr_3
CREATEPROCdbo.pr_3
AS
SETNOCOUNTON;
DECLARE@errint;
BEGINTRY
--we are now modern
PRINT'dbo.pr_3: We are now about to do a division 0 error'
SELECT1/0;
ENDTRY
BEGINCATCH
--clean up and log etc.
PRINT'dbo.pr_3: We are cleaning up, rewinding, blah, blah, and let''s THROW';
THROW
ENDCATCH
GO--end dbo.pr_3
At the same time in the error handling code of dbo_pr1, let's select out the error message as well as error number, right before we raise the exception: SELECT ERROR_MESSAGE() AS Msg, ERROR_NUMBER() AS ErrNo, and then EXEC dbo.pr_Caller. All should be as before, and in the Results tab in SSMS you should see:
Figure 2:Correct Error Number and Message
By receiving 8134 as error number we can see that THROW actually does what it is supposed to. However what happens if we were to edit dbo.pr_1 to also THROW, seeing that dbo.pr_Caller is still doing old style error handling:
CREATEPROCdbo.pr_1
AS
SETNOCOUNTON;
DECLARE@errint;
--add the new "cool" errorhandling
BEGINTRY
--do some stuff
--do some other stuff
--then call into dbo.pr_2
PRINT'dbo.pr_1: We are now about to execute dbo.pr_2'
EXECdbo.pr_2
ENDTRY
BEGINCATCH
--clean up and log etc.
SELECTERROR_MESSAGE()ASMsg,ERROR_NUMBER()ASErrNo;
PRINT'dbo.pr_1: We are cleaning up, rewinding, blah, blah, and THROWING';
THROW;
RETURN;
ENDCATCH
GO--end dbo.pr_1
Execute the pr_Caller, and notice the output: there is nothing there from dbo.pr_Caller. If THROW is used down in the call chain somewhere, there has to be a calling proc using the new error handling!
Summary
So in summary:
TRY CATCH blocks ARE good!
However, be careful when mixing new TRY CATCH with "old" @@ERROR
You need to ensure all nested procedures called inside the TRY block is also using TRY CATCH.
If raising an error in a CATCH block, ALWAYS follow the RAISERROR with a RETURN (no value).
Unless you can guarantee that your code will always use TRY CATCH, stay away from THROW.
SET XACT_ABORT defines whether a transaction is automatically rolled back when a T-SQL statement raises a run-time exception, and when you read posts from prominent SQL bloggers you quite often see that they recommend to always have XACT_ABORT set to ON. From the title of this post you may get the impression that I do not necessarily agree, and to an extent you may be right. So, let us see ...
Background
First of all; as with a post a while ago about SQL Server Error Handling Gotcha's, this post is based on real world experiences based on the production OLTP databases we have here at Derivco.
Derivco's main OLTP production database has around 5,000 stored procedures, where a small procedure has about 600 - 800 LOC, and a big procedure can have 3,000 - 4,000 LOC. The procedures are also quite heavily nested, where it is not uncommon to have a call chain of 10 - 15 procedures. It is not only one team working on the procedures, but multiple teams are maintaining and developing procedures.
So, back to the issue at hand, and let's begin looking at why we have XACT_ABORT in the first place? That has to do with transactions and SQL exceptions; remember back before SQL Server 2005 and TRYCATCH, an exception did not normally stop execution of a batch, even though the execution of the statement stopped. Let us look at some code for this, and let's start with creating a couple of tables with a foreign key constraint between them:
Note: Most of the code in this post can be downloaded from here
Table Creation
-- this database must be created before executing this
USEErrTestDB;
GO
SETNOCOUNTON;
GO
--this DROP IF EXISTS syntax requires SQL Server 2016
As you see, we are creating a couple of tables, and then inserts some data into the primary table dbo.tb_Order. Now, if we write some code inserting data into dbo.tb_OrderDetail, inside a transaction, and we cause an exception to happen - what will the result be:
Transaction With Error
SETNOCOUNTON;
GO
BEGIN
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID')-- this should cause a fk exception
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3')
COMMIT
SELECT*FROMdbo.tb_OrderDetail
END
GO
Code Snippet 2:Error
From the code we see how we:
start a transaction
insert for OrderID 1
try to insert for OrderID 5
this causes a foreign key exception
insert for OrderID 3
commit the transaction
SELECT from the table
The result from executing the code is that we get an foreign key exception raised, and the INSERT statement terminated as in Figure 1:
Figure 1:Foreign Key Exception
However, when looking at the result from the SELECT statement, we see how the first and third INSERT succeeded:
Figure 2:SELECT After Exception
So, as mentioned before, the exception did not affect the transaction, and anything after the exception executed as nothing had happened, plus the transaction was committed. This may not be the behavior you really wanted, e.g. you expected the transaction to roll back when an exception happened.
If that's the behavior you wanted, there are a couple (actually 3) of ways to achieve it:
Check @@ERROR after each INSERT, and then ROLLBACK and RETURN.
If you are in an environment using SQL Server 2005+, catch the exception with BEGIN TRY ... END TRY and BEGIN CATCH ... END CATCH, and do a ROLLBACK.
Use XACT_ABORT.
XACT_ABORT
By using XACT_ABORT we can ensure that the executing batch is terminated as well as any transaction being rolled back if an exception is raised, by setting SET XACT_ABORT ON, and then executing your code:
Transaction Causing FK Exception with XACT ABORT ON
SETNOCOUNTON;
GO
--just clean up so we don't have any "baggage"
TRUNCATETABLEdbo.tb_OrderDetail
SETXACT_ABORTON;
BEGIN
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID')-- this should cause a fk exception
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3')
COMMIT
SELECT*FROMdbo.tb_OrderDetail
END
GO
Code Snippet 3:Executing with XACT_ABORT ON
The code looks almost like in Code Snippet 2, with the addition that we switch on XACT_ABORT in the beginning of the batch, oh and yes - we are also cleaning up the dbo.tb_OrderDetail table with a TRUNCATE TABLE command. When executing the code you almost get the same output as from Code Snippet 2, except for the fact that the output message does not say anything about statement termination:
Figure 3:Output Message after Executing with XACT_ABORT ON
Also, there is no Result tab in the output, which indicates that the SELECT statement at the end of the batch did not execute, e.g. the exception caused a batch termination, due to XACT_ABORTbeing ON. So what about the transaction, remember that before we switched XACT_ABORTON, the first and second INSERT statement succeeded. We can safely assume that in this example the third INSERT did not succeed, as the batch was terminated, but what about the first? Well, let's see; go ahead and execute the SELECT * FROM dbo.tb_OrderDetail and see what the result is. You should get something like in Figure 4:
Figure 4:Result After XACT_ABORT
No rows coming back, XACT_ABORT rolled back the transaction as well as terminating the batch! That is fairly cool! What about something - somewhat (not much) - more realistic than just a batch execution; like XACT_ABORT and stored procedures. Below in Code Snippet 4, is code to create three stored procedures. The top level procedure (dbo.pr_1) switches XACT_ABORT and then goes on to start a transaction, do an insert and call dbo.pr_2, which in turns calls dbo.pr_3. The last procedure - dbo.pr_3 - generates a foreign key exception:
NOTE: The transaction handling in all the procs, in all examples, is very much simplified, whereby the procs being called by the top-level proc is not doing anything with transactions, as the transaction should only be committed/rolled back by the proc that started the transaction. See my blog post from a couple of years ago about proper transaction handling.
Stored Procedures
-- proc 1
CREATEPROCEDUREdbo.pr_1
AS
SETNOCOUNTON;
SETXACT_ABORTON;
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
EXECdbo.pr_2;
COMMITTRAN;
GO
--proc 2
CREATEPROCEDUREdbo.pr_2
AS
SETNOCOUNTON;
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3')
EXECdbo.pr_3;
GO
-- proc 3
CREATEPROCEDUREdbo.pr_3
AS
SETNOCOUNTON;
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID');-- this should cause a fk exception
GO
Code Snippet 4:Procedures with XACT_ABORT
If you are copying and pasting the code above, make sure you create the procs in opposite order to what is in the Code Snippet.
Let's see what happens when we execute dbo.pr_1:
Proc Execution
-- code for cleanup
-- TRUNCATE TABLE dbo.tb_OrderDetail
EXECdbo.pr_1;
GO
-- execute this SELECT after you have executed the proc above
-- SELECT * FROM dbo.tb_OrderDetail
GO
Code Snippet 5:Execution of the Procedures
The result is exactly the same as when we executed the code in Code Snippet 3. So, even when we execute multiple procedures under the same SPID, the XACT_ABORT ensures that the batch (call chain) is terminated and the transaction rolls back!
How cool is that, what is there not to like about automatic transaction rollback when an exception happens!
What Could Possibly Go Wrong?!
Right let's have a look at a couple of scenarios where XACT_ABORT may not be the answer to your prayers.
IF(@@ERROR<>0)
We'll start where we are in a situation where we still are doing SQL Server error-handling the old way, by checking @@ERROR after execution of statements. This could be a scenario where we have quite a few old procedures, which have not been update to TRY ... CATCH yet. The procedures look like so:
Old Style Error Handling
--proc 1
CREATEPROCEDUREdbo.pr_1
AS
SETNOCOUNTON;
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
EXECdbo.pr_2;
IF(@@ERROR<>0)
BEGIN
PRINT'dbo.pr_1: We are handling an error, cleaning up, and rolling back'
ROLLBACKTRAN;
RETURN
END
PRINT'Here we are doing something which
relies on the execution of dbo.pr_2 being successful'
COMMITTRAN;
GO
--proc 2
CREATEPROCEDUREdbo.pr_2
AS
SETNOCOUNTON;
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3')
EXECdbo.pr_3;
IF(@@ERROR<>0)
BEGIN
PRINT'dbo.pr_2: We are handling an error, cleaning up, and raising'
VALUES(5,'Details for Invalid OrderID');-- this should cause a fk exception
IF(@@ERROR<>0)
BEGIN
PRINT'dbo.pr_3: We are handling an error, cleaning up, and raising'
RAISERROR('dbo.pr_3: Error in dbo.pr_3',16,-1);
RETURN
END
GO
Code Snippet 6:Procedures with Old Style Error Handling
They do not look much different than the procedures in my blog post a while ago about "gotcha's" in error handling. The procedures are being "good citizens", and check for errors after executing something that could go wrong, and if there is an error, they re-wind, clean up, and raise the exception up the call-chain. When executing dbo.pr_1, as in Code Snippet 5, you would see something like so:
Figure 5:Executing Procs Old Style Error Handling
We see how the exception happens and then how each proc is handling the exception, cleaning up, and re-raising. When dbo.pr_1 receives the error, it also rolls back the transaction. If everythig had executed successfully, the dbo.pr_1 proc would have gone on executing code after the error-handling block. In this case we can see it did not do that. Then, when executing the SELECT statement, no results are coming back - as everything has been rolled back.
What would happen if the dbo.pr_1 proc were to be modified to use XACT_ABORT? Let's say a developer has heard about XACT_ABORT, and think it sounds cool, so while he is doing other changes to the proc, he also changes it to use XACT_ABORT:
Proc Edited to Use XACT_ABORT
DROPPROCEDUREIFEXISTSdbo.pr_1;
GO
CREATEPROCEDUREdbo.pr_1
AS
SETNOCOUNTON;
SETXACT_ABORTON;
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
EXECdbo.pr_2;
IF(@@ERROR<>0)
BEGIN
-- we have taken out the rollback as XACT_ABORT is ON
-- however we still need to cleanup
PRINT'dbo.pr_1: We are handling an error, cleaning up'
RETURN
END
PRINT'Here we are doing something which
relies on everything being successful'
COMMITTRAN;
GO
Code Snippet 7:dbo.pr_1 Using XACT_ABORT
Not much have changed, the developer:
added SET XACT_ABORT ON before the BEGIN TRANSACTION
took out the ROLLBACK in the error-handling block (as XACT_ABORT is used)
we still need to do cleanup in there though
What is the result now when executing dbo.pr_1:
Figure 6:Executing Procs Using XACT_ABORT
Whoa, no clean-up, rewinds, anything! I guess that should be expected seeing that XACT_ABORT terminates the batch, and rolls back the transaction. However this is one of the reasons I do not like XACT_ABORT: you have no control over what happens when an error occur!
RAISERROR
So far the errors we have seen are errors from T-SQL statements, what if we were to raise an exception through RAISERROR? The answer to that is that RAISERROR will not cause XACT_ABORT to trigger! This means we can be in a very messed up state transaction wise. So if we use XACT_ABORT we need to be very careful how we handle exceptions, and we cannot solely rely on it to automatically do a ROLLBACK.
NOTE: Using THROW would cause XACT_ABORT to work as intended, however that would require SQL Server 2012, and THROW in itself adds its own issues. See my blog post for more around that.
TRY ... CATCH
What happens if we are in a TRY ... CATCH situation; e.g. using somewhere in the call-chain the exception handling capabilities introduced in SQL Server 2005?
See my blog post about what issues you can run into with mixing and matching error-handling styles.
So let us edit dbo.pr_3 to do "new" error-handling, and let the other procs stay the same:
Proc with TRY ... CATCH
DROPPROCEDUREIFEXISTSdbo.pr_3;
GO
CREATEPROCEDUREdbo.pr_3
AS
SETNOCOUNTON;
BEGINTRY
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID');-- this should cause a fk exception
ENDTRY
BEGINCATCH
PRINT'dbo.pr_3: We are handling an error, cleaning up, and raising'
RAISERROR('dbo.pr_3: Error in dbo.pr_3',16,-1);
RETURN
ENDCATCH
GO
Code Snippet 8:TRY ... CATCH in dbo.pr_3
Here it is the last proc in the call-chain that are using TRY ... CATCH, and as it is doing proper exception handling it knows that it did not start the transaction, so in the error handling code it just raises the error. The result is the following:
Figure 7:XACT_ABORT and TRY ... CATCH
Ooops, we really are in a messed up state. I guess that is to be expected seeing what we discovered above regarding RAISERROR. Once again, we need to be very careful what we do when we use XACT_ABORT. Oh, and what would the result be if we only changed dbo.pr_1 to use TRY ... CATCH, e.g roll back the change in dbo.pr_3, and add the "new" style exception handling in dbo.pr_1:
Top Level Proc with XACT_ABORT and TRY ... CATCH
DROPPROCEDUREIFEXISTSdbo.pr_1;
GO
CREATEPROCEDUREdbo.pr_1
AS
SETNOCOUNTON;
SETXACT_ABORTON;
BEGINTRY
BEGINTRANSACTION
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
EXECdbo.pr_2;
PRINT'Here we are doing something which
relies on the execution of dbo.pr_2 being successful'
COMMITTRAN
ENDTRY
BEGINCATCH
PRINT'dbo.pr_1: We are handling an error, cleaning up'
RETURN
ENDCATCH
GO
Code Snippet 8:TRY ... CATCH in dbo.pr_1
Notice that we in the CATCH block we are not doing rolling back the transaction as we rely on XACT_ABORT to handle that. When executing the result is:
Figure 8:Top Level TRY ... CATCH and XACT_ABORT
From the result we see how we immediately ended up in the TRY ... CATCH block in dbo.pr_1! This indicates that TRY ... CATCHoverridesXACT_ABORT! In reality there is no use having XACT_ABORT and TRY ... CATCH in the same proc!
In fact, I would argue that when we have TRY ... CATCH we don't need XACT_ABORT, as we can decide what to do with the transaction in the CATCH block!
We have now seen quite a few examples where XACT_ABORT may not be ideal. My biggest "gripe" with XACT_ABORT is not any of those...
All Errors are Equal, Some are More Equal then Others
I am paraphrasing George Orwell above, and that phrase summarizes why I do not like XACT_ABORT. Let me explain...
If we go back to what the code looked like at Code Snippet 6. We had three procs which did proper error handling and all was good. Let us assume these procs were some procs for a financial institution where they were called for deposits. We then realized that we needed some code that did something that were not vital for the actual deposit process, but we still needed it to execute together with the other procs (this may be logging, etc). So we introduce a new proc (call it dbo.pr_Logging) into the call chain, and in that proc we make sure we handle any errors, because we do not want to affect the deposit process. We handle the errors in the "old" way, as we do not want to mix "old" and "new". All is well and good!
However, we now come to the same scenario we saw in Code Snippet 7; the developer who had heard about XACT_ABORT. So the developer introduces the XACT_ABORT as in Code Snippet 7.
What happens now if an exception happens in dbo.pr_Logging? The batch is terminated and the transaction is rolled back. So a non-vital error is now causing the transaction (the deposit) to fail! Ouch!!!!
Summary
I am against XACT_ABORT because:
You are losing control of what to do when an exception happens
It does not play well with TRY ... CATCH
Non-vital exceptions causes the whole transaction to roll back!
Throughout the week, I read a lot of blog-posts, articles, etc., that has to do with things that interest me:
data science
distributed computing
SQL Server
transactions (both db as well as non db)
and other "stuff"
This is the "roundup" of the posts that has been most interesting to me. Oh, and if you wonder if you have missed Interesting Stuff - Week #1. seeing that this post is named Interesting Stuff - Week #2, you haven't. They are numbered by calendar week number, and I started the second week of January :).
Data Science
SQL Server R Services. The first in a series of articles why Microsoft why they built R in SQL Server, and how it woks under the covers. I really look forward to reading more about this.
What can we learn from StackOverflow data?. A post from Revolution Analytics blog, where they discuss what insights can be had from StackOverflow data. For you who don't know, Revolution Analytics was acquired by Microsoft in 2015, and a lot of what Revolution Analytics dis are now part of Microsoft R Services, etc.
The Great A.I. Awakening. A post from New York Times about how Google used artificial intelligence to enhance Google Translate.
Why do Decision Trees Work?. This post is very informative about how and - more importantly - decision trees work.
Distributed Computing
Apache Hadoop YARN: Yet another resource negotiator. A discussion of the requirements that drove the design of YARN and the high-level approach. This article is from the morning paper, where every weekday @adriancolyer dissects a white-paper from the world of Computer Science.
Chaos Engineering. More about chaos engineering. This article is from InfoQ, covering how Netflix is doing chaos engineering.
Building a Microservices Platform with Kubernetes. An InfoQ presentation by Matthew Mark Miller where he discusses Kubernetes’ primitives and microservices patterns on top of them, including rolling deployments, stateful services and adding behaviors via sidecars.
Throughout the week, I read a lot of blog-posts, articles, etc., that has to do with things that interest me:
data science
data in general
distributed computing
SQL Server
transactions (both db as well as non db)
and other "stuff"
This is the "roundup" of the posts that has been most interesting to me, this week.
This week there will be quite a few links to white-papers from this years The Conference on Innovative Data Systems Research (CIDR). It was started in 2002 by very illustrious people from the database industry: Michael Stonebraker, Jim Gray, and David DeWitt! The conference gives the database community a venue to present groundbreaking and innovative data systems architectures. This year it was held January 8 - 11, and you can find all the presentations here.
I have had a quick glance through the white-papers and following are the ones that I am interested in and have had a chance to look at in some details:
Data Ingestion for the Connected World. Discussion around new architecture for doing ETL in a world where real-time data is of out-most importance. The solution, which I am really, really interested in getting to know more about, centers around:
S-Store which is a streaming OLTP engine, which seeks to seemlessly combine online transactional processing with push-based stream processing for real-time applications.
Evolving Databases for New-Gen Big Data Applications. Presenting a system for handling high-volume transactions while executing complex analytics queries concurrently in a large-scale distributed big data platform.
The Data Civilizer System. As a data scientist you probably spend most of your time finding, preparing and cleaning data, instead of doing "real" work! This paper presents Data Civilizer, a system to help data scientists to:
discover data sets from large number of tables
link relevant data sets
compute answers from the data stores that holds the discovered data
clean the desired data
iterate through the tasks using a workflow system
As mentioned before, the above papers were the ones of interest that I had a chance to at least skim through. There are a wealth more of papers at the site, so go an have a look. I also want do a shout-out to the morning paper, which - the last week - has started dissecting these papers. So if you don't have time to go through all the papers yourself, browse to the morning paper, and get the papers served to you!
Apache Kafka: Getting Started. Apache Kafka is one of the more popular message brokers out there (it is much more than a message broker), and Kafka appears in most solutions for distributed applications. Just see above in Data Ingestion for the Connected World! This post is a very good introduction how to get started with Kafka.
Reactive Kafka. Kafka again. This time from InfoQ, and a presentation about how the new reactive streams interface for Kafka can be used to build robust applications in the microservices world.
SQL Server
Automate Delivery of SQL Server Production Data Environments Using Containers. Exactly as what the title says; how containers can be used in the SQL Server World. This is something that is of very much interest to us here at Derivco, seeing how many SQL Server instances we have out in the world (we have one of the biggest SQL Server installations world-wide).
That's all for this week. I hope you enjoy what I did put together. If you have ideas for what to cover, please comment on this post or ping me.
Just to set things straight, the title of this post has nothing to do with US politics, but the infinitely more important (and exciting) subject of transactions in SQL Server and the concept of doomed transactions. Why I came across the idea for this post was due to a discussion I had with a colleague of mine - Sameer Chunilall - who didn't agree with my post a while ago about XACT_ABORT, he believes it is a good thing (mostly), where I believe it is a bad thing (mostly).
We argued discussed at length, and then decided that we both were right. Or rather I decided I was right, and he decided he was right :). Jokes aside, during the discussions the concept of doomed transactions were brought up, and that led me to writing this blog post.
Before we go any further, I have written a couple (three actually) posts that deal with transactions and/or error-handling in SQL Server, so if you want to refresh your memory they can be found here (in chronological order):
In SQL Server you execute statements and batches. A statement is what it says it is, a single T-SQL statement, like:
Statement Execution
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1');
Code Snippet 1:T-SQL Statement
A batch is what is executed at a point in time from an application (SSMS, ADO.NET, etc.):
Batch Execution
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1');
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID');
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3');
GO
Code Snippet 2:T-SQL Batch
NOTE: The GO statement in Code Snippet 2, is an SSMS "thing". When executing code from a script, theGO statement denotes batches.
When executing a stored procedure, that is also a batch. If a procedure calls other procedures, they are all executing inside the same batch. The code below shows 4 procedures we will use going forward:
Procedures
-- the DROP ... IF EXISTS only works on SQL SERVER 2016+
DROPPROCEDUREIFEXISTSdbo.pr_Caller
DROPPROCEDUREIFEXISTSdbo.pr_1;
DROPPROCEDUREIFEXISTSdbo.pr_2;
DROPPROCEDUREIFEXISTSdbo.pr_3;
GO
CREATEPROCEDUREdbo.pr_3
AS
BEGIN
SETNOCOUNTON;
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(3,'Details for OrderID 3')
END
GO
CREATEPROCEDUREdbo.pr_2
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_2: Before Insert'
--this should just work
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(2,'Details for OrderID 2');
---- this should cause a fk exception
--INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
--VALUES(5, 'Details for Invalid OrderID');
---- invalid object name
--SELECT * FROM dbo.tb_MyTable;
---- Conversion failure
-- DECLARE @n int;
-- SELECT @n = CONVERT(int,'ABC');
PRINT'dbo.pr_2: Before EXEC dbo.pr_3'
EXECdbo.pr_3;
END
GO
CREATEPROCEDUREdbo.pr_1
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_1: Before Insert'
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(1,'Details for Order 1')
PRINT'dbo.pr_1: Before EXEC dbo.pr_2'
EXECdbo.pr_2;
END
GO
CREATEPROCEDUREdbo.pr_Caller
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_Caller: Before Begin TX'
BEGINTRANSACTION
PRINT'dbo.pr_Caller: Before EXEC dbo.pr_1'
EXECdbo.pr_1;
PRINT'dbo.pr_Caller: Before Commit TX'
COMMIT
END
GO
Code Snippet 3:Call Chain of Procedures
As we can see, dbo.pr_Caller starts a transaction, calls dbo.pr_1, which in turn calls dbo.pr_2, which finally calls dbo.pr_3. When all is "said and done", dbo.pr_Caller commits the transaction. The procedure dbo.pr_2 is the "dodgy" procedure in this call chain, and we will use it to simulate some error conditions that will result in various termination types. As you can see in Code Snippet 3, dbo.pr_2 has some commented out code, and it is this code that will cause terminations. Initially we'll execute the code as is, and this should not cause any errors:
Execution of Procedures
TRUNCATETABLEdbo.tb_OrderDetail;
GO
EXECdbo.pr_Caller;
GO
SELECT*FROMdbo.tb_OrderDetail;
GO
Code Snippet 4: Batch Executions
NOTE: The code above starts with TRUNCATE TABLE we do that just to make sure everything is cleaned up before execution. Oh, and BTW - how many batches are executed above? Answer in comments or email.
When executing the above you should see three rows coming back from the SELECT statement, all is good:
Figure 1:Procedure Execution No Errors
So what happens now if we were to ALTER proc 2 a bit, comment out the insert for OrderID 2, and uncomment the insert for OrderID 5. There is no order with that id, so it should result in a foreign key constraint error. The proc should look like so:
Alter Proc
ALTERPROCEDUREdbo.pr_2
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_2: Before Insert'
----this should just work
--INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
--VALUES(2, 'Details for OrderID 2');
-- this should cause a fk exception
INSERTINTOdbo.tb_OrderDetail(OrderID,SomeDetail)
VALUES(5,'Details for Invalid OrderID');
---- invalid object name
--SELECT * FROM dbo.tb_MyTable;
---- Conversion failure
-- DECLARE @n int;
-- SELECT @n = CONVERT(int,'ABC');
PRINT'dbo.pr_2: Before EXEC dbo.pr_3'
EXECdbo.pr_3;
END
GO
Code Snippet 5:Proc Which Will Cause FK Violation
After ALTER:ing the proc and executing as in Code Snippet 4, we get something like:
Figure 2:FK Error After Procedure Execution
So we got a FK violation error, but we can also see that we continued the execution in dbo.pr_2, and called dbo.pr_3. Furthermore, the result gives us two rows back, from dbo.pr_1 and dbo_pr_3:
Figure 3:Result After FK Error
Statement Termination
What we just have seen is statement termination. The statement causing an error stopped executing, but we continued executing - even within the same proc - straight after that statement. Furthermore, the error had no negative impact on the transaction. This may or may not be what you expect and want.
I guess that most of you who read this have heard about statement termination before, so what we just have done should not come as any surprise.
Some of the errors that can cause statement termination are:
Most of CONSTRAINT errors:
NOT NULL
PRIMARY KEY and FOREIGN KEY errors
CHECK CONSTRAINT
Errors raised by the user
Quite a few more :)
Scope Termination
Scope Termination is probably not as well known as statement termination. A scope termination is when SQL Server terminates the statement that caused the exception and subsequent execution within the same scope. In the examples we are using, scope would be an individual procedure. So, let us have a look at an scope termination example, let us ALTER our "naughty" procedure dbo.pr_2 and comment out the statement which caused the FK violation, and un-comment where the procedure does a SELECT from the non-existent table dbo.tb_MyTable:
Alter For Scope Termination
ALTERPROCEDUREdbo.pr_2
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_2: Before Insert'
----this should just work
--INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
--VALUES(2, 'Details for OrderID 2');
---- this should cause a fk exception
--INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
--VALUES(5, 'Details for Invalid OrderID');
-- invalid object name
SELECT*FROMdbo.tb_MyTable;
---- Conversion failure
-- DECLARE @n int;
-- SELECT @n = CONVERT(int,'ABC');
PRINT'dbo.pr_2: Before EXEC dbo.pr_3'
EXECdbo.pr_3;
END
GO
Code Snippet 6: SELECT from Non-Existent Table
When you execute as in Code Snippet 4, the outcome is:
Figure 4:Scope Abort Error
As expected an error happened, but compared to the statement termination example, dbo.pr_2 did not continue executing (we did not see dbo.pr_2: Before EXEC dbo.pr_3). The statement that caused the error was terminated AND all subsequent statements within that scope (procedure). However, the batch continues and dbo.pr_Caller committed the transaction. When you look at the Results tab in SSMS you will see one row returning from the SELECT statement; the insert done by dbo.pr_1.
So, what causes scope termination? I have tried to look into that, but so far the only error type I have found termination the scope is when you try to access a missing object. If you know more types, please email me, and I can update this post.
NOTE: Neither statement termination, nor scope termination have any effect on a transaction.
Error Handling and Scope Termination
An interesting aspect of scope termination is how it is being handled (or not) by error handling. From my previous posts about errors, (gotchas, and XACT_ABORT), we see how either IF(@@ERROR <> 0 ), or TRY ... CATCH catch exceptions. How about scope termination errors? You would expect them to be handled the same way as statement termination errors, as they do have the same severity (16), as can be seen from Figure 3, and Figure 4. In fact that is not the case! It turns out that an IF(@@ERROR <> 0) will not catch the error, whereas a TRY ... CATCH block will!
Batch Termination
After having covered statement termination and scope termination above, I do think that it is pretty clear what batch termination is. Some code to show this; once again in dbo.pr_2, comment out the SELECT statement against the no existing table and un-comment the part where we try to do a CAST conversion:
Alter Proc for Batch Termination
ALTERPROCEDUREdbo.pr_2
AS
BEGIN
SETNOCOUNTON;
PRINT'dbo.pr_2: Before Insert'
----this should just work
--INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
--VALUES(2, 'Details for OrderID 2');
---- this should cause a fk exception
-- INSERT INTO dbo.tb_OrderDetail(OrderID, SomeDetail)
-- VALUES(5, 'Details for Invalid OrderID');
---- invalid object name
-- SELECT * FROM dbo.tb_MyTable;
--- Conversion failure
DECLARE@nint;
SELECT@n=CONVERT(int,'ABC');
PRINT'dbo.pr_2: Before EXEC dbo.pr_3'
EXECdbo.pr_3;
END
GO
Code Snippet 7:Proc Which Will Cause CAST Conversion Error
When executing this (once again a in Code Snippet 4), this is what we get:
Figure 5:Batch Termination Error
When looking at the output as per in Figure 5, we can see that no more execution happened in dbo.pr_2, as was also the case in scope-termination and Figure 4, BUT we do not see any further execution in dbo.pr_Caller either! The batch completely terminated. But wait a second; what about the transaction that was originally started in dbo.pr_Caller? That transaction has been rolled back automatically, when we exited the batch (more about that later).
Errors that can cause batch termination are:
Conversion errors
Deadlocks
Error Handling and Batch Termination
As with scope termination, IF(@@ERROR <> 0) will not catch the error that caused the batch termination, but TRY ... CATCH will. So, let's see what happens when we introduce TRY ... CATCH in dbo.pr_Caller:
Proc With TRY ... CATCH Block
ALTERPROCEDUREdbo.pr_Caller
AS
BEGIN
SETNOCOUNTON;
BEGINTRY
PRINT'dbo.pr_Caller: Before Begin TX'
BEGINTRANSACTION
PRINT'dbo.pr_Caller: Before EXEC dbo.pr_1'
EXECdbo.pr_1;
PRINT'dbo.pr_Caller: Before Commit TX'
COMMIT
ENDTRY
BEGINCATCH
PRINT'In catch block'
ENDCATCH
END
GO
Code Snippet 8:TRY ... CATCH and Batch Termination
We ALTERdbo.pr_Caller to have a TRY ... CATCH, but we do not do anything other than a PRINT statement. Remember, when we didn't have any TRY ... CATCH, the transaction was automatically rolled back. It is a little bit different now when we execute it as in Code Snippet 4:
Figure 5:Uncommittable Transaction
What happened here? All of a sudden we get quite a few error messages, and what is this about Uncommittable transaction at the very end? The short story is that as soon as you introduce TRY ... CATCH and you have active transactions - you need to decide what to do with that transaction.
OK makes sense. In this case, I don't really care what went wrong, and I want to commit the transaction anyway. I conveniently don't pay any attention to the part of uncommittable in the error message. After all - this is what I can do if I get a statement termination or scope termination, so why not do it here too! I ALTER the procedure to do COMMIT TRAN in the CATCH block straight after the PRINT statement, and then I execute:
Figure 6:Current Transaction Cannot be Committed
I am in trouble now. This time I am really told that I am doing something wrong: "The current transaction cannot be committed and cannot support operations
that write to the log file. Roll back the transaction". What is this?
Doomed (a.k.a. "Oh, Oh, I am so up the cr33k")
The errors we see in both Figure 5 as well as in Figure 6 are due to that SQL Server decides - for one reason or another - that it cannot commit the transaction. The transaction is doomed, and the only thing that can be done is to roll it back. It is not straight forward when an error causes a doomed transaction as the way SQL Server handles errors are case by case. Rule of thumb though is that in most cases a doomed transaction is due to some error that has caused a batch termination.
NOTE: To further drive home that SQL handles errors on a case by case basis, all errors we have seen so far (caused by statement, scope and batch terminations), have had a severity of 16.
Just to prove that we can recover from a batch termination without errors, we ALTER the dbo.pr_Caller procedure, replace the COMMIT TRAN with ROLLBACK TRAN, and execute. The outcome will be completely different:
Figure 6:Rollback Doomed Transaction
As Figure 6 shows, no "nasty" errors - all is OK! So what do we do if we sometimes want to commit the transaction if it is not doomed even if there has been an error, or rather - how can we figure out whether a transaction can be committed or not?
XACT_STATE()
The way to determine if a transaction can be committed or not is to use XACT_STATE(). The XACT_STATE() is a scalar function and it reports on the state of the current transaction. There are 3 possible return values:
-1: a user transaction is active, but it is doomed, and it can only be rolled back
0: no user transaction is active
1: a user transaction is active, it can be committed or rolled back.
To see an example of this ALTER the dbo.pr_Caller proc's CATCH block to look something like Code Snippet 9 below and then execute.
XACT_STATE
BEGINCATCH
DECLARE@statesmallint=(SELECTXACT_STATE());
PRINT'In catch block and XACT_STATE = '+CAST(@stateasvarchar(2));
IF(@state=-1)
BEGIN
PRINT'We are rolling back'
ROLLBACKTRAN;
END
ELSEIF(@state=1)
BEGIN
PRINT'We are committing'
COMMITTRAN
END
ELSE
PRINT'No transaction available'
ENDCATCH
Code Snippet 9:Using XACT_STATE()
After execution the output would be like so:
Figure 7:Rollback Doomed Transaction
As we see from Figure 7, we ended up in the CATCH block, XACT_STATE was -1, and the transaction was rolled back. You can if you want ALTER the "naughty" proc dbo.pr_2, and comment out the statement causing the batch termination and un-comment the statement which creates the statement termination. When executing, you should now get an output like so:
Figure 8:Rollback Doomed Transaction
Here we had decided that even if an exception was raised, we wanted to commit the transaction, unless it was doomed.
NOTE:XACT_STATE can be used outside TRY ... CATCH, so you can use it even with "old style" error handling.
XACT_ABORT
I started this blog-post by talking about XACT_ABORT, and how I discussed with Sameer if it was good or bad. We have now come full circle and we are back to XACT_ABORT. You are probably asking yourself how that fits into here?
The answer to that is that if you switch on XACT_ABORT, even statement termination errors will cause the transaction to be doomed! To test this, ALTER the calling proc dbo.pr_Caller and insert a SET XACT ABORT ON at the beginning of the proc, underneath the SET NOCOUNT ON. The first few lines of the proc should look like so:
XACT_ABORT ON
ALTERPROCEDUREdbo.pr_Caller
AS
BEGIN
SETNOCOUNTON;
SETXACT_ABORTON;
BEGINTRY
Code Snippet 10:Setting XACT_ABORT ON
If you haven't already ALTER:ed dbo.pr_2 to cause a foreign key exception (statement termination and not a "doomable" error), do so - as discussed between Figure 7 and Figure 8. When you now execute you will get the same output as in Figure 7.
Finally, it is quite common to hear that triggers can be an issue, as they are rolling back transactions if an error happens in the trigger. The reason for this is that when a trigger executes, it automatically sets XACT_ABORT ON.
I am not completely certain of the reason for this, but I guess it is a good "defensive" measure. So, if you don't want this behavior, you can do a SET XACT_ABORT OFF in your triggers.
Summary
Transactions are doomed:
When an exception happens which causes a batch termination
For any exception when XACT_ABORT is ON.
When SQL Server feels like it. :)
Exception handling in SQL Server is NOT straight forward, especially when mixed with transactions!
Throughout the week, I read a lot of blog-posts, articles, etc., that has to do with things that interest me
data science
data in general
distributed computing
SQL Server
transactions (both db as well as non db)
and other "stuff"
This is the "roundup" of the posts that has been most interesting to me, this week.
This week it is mostly data science, so without further ado, let's get cracking:
Data Science
Upcoming R Conferences. A list of upcoming R conferences around the world. Among the conferences it lists the second ever satRday, this year held in Cape Town. I will be speaking there, and I do believe there still are tickets left. Check here for more.
Making Sense of Stream Processing. A download link for an eBook covering how stream processing can make your data processing systems more flexible and less complex. I include it here as the book discusses Kafka (which I think is awesome, Kafka I mean).
SQL Server
Introducing SQL Server on Linux. A YouTube video about SQL Server on Linux, including how you can: download and install SQL Server on a Linux Virtual Machine; run your SQL Server-based apps inside of Docker containers and improve the performance of your applications.
So this is my shameless self promotion part. I have three blog-posts about error handling on SQL Server. Personally I think they are well worth reading :). In chronological order:
Throughout the week, I read a lot of blog-posts, articles, etc., that has to do with things that interest me:
data science
data in general
distributed computing
SQL Server
transactions (both db as well as non db)
and other "stuff"
This is the "roundup" of the posts that has been most interesting to me, this week.
Distributed Computing
Life Beyond Distributed Transactions. An excellent piece about distributed transactions in large scale systems. As a side note; the queue.acm.org is a goldmine if you are interested in enterprise computing related papers.
JSON data in clustered column store indexes. Jovan has written a really nice post how Clustered Column Store indexes can give you compression and query performance benefits for JSON data store in SQL Server.
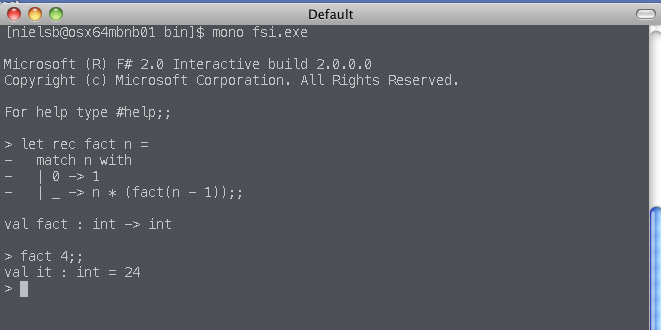
 Figure 1:Output from Error Procs
Figure 1:Output from Error Procs Figure 2:Output from Altered Error Procs
Figure 2:Output from Altered Error Procs Figure 2:Correct Error Number and Message
Figure 2:Correct Error Number and Message Figure 1:Foreign Key Exception
Figure 1:Foreign Key Exception Figure 2:SELECT After Exception
Figure 2:SELECT After Exception Figure 3:Output Message after Executing with XACT_ABORT ON
Figure 3:Output Message after Executing with XACT_ABORT ON Figure 4:Result After XACT_ABORT
Figure 4:Result After XACT_ABORT Figure 5:Executing Procs Old Style Error Handling
Figure 5:Executing Procs Old Style Error Handling Figure 6:Executing Procs Using XACT_ABORT
Figure 6:Executing Procs Using XACT_ABORT Figure 7:XACT_ABORT and TRY ... CATCH
Figure 7:XACT_ABORT and TRY ... CATCH Figure 8:Top Level TRY ... CATCH and XACT_ABORT
Figure 8:Top Level TRY ... CATCH and XACT_ABORT Figure 1:Procedure Execution No Errors
Figure 1:Procedure Execution No Errors Figure 2:FK Error After Procedure Execution
Figure 2:FK Error After Procedure Execution Figure 3:Result After FK Error
Figure 3:Result After FK Error Figure 4:Scope Abort Error
Figure 4:Scope Abort Error Figure 5:Batch Termination Error
Figure 5:Batch Termination Error Figure 5:Uncommittable Transaction
Figure 5:Uncommittable Transaction Figure 6:Current Transaction Cannot be Committed
Figure 6:Current Transaction Cannot be Committed Figure 6:Rollback Doomed Transaction
Figure 6:Rollback Doomed Transaction Figure 7:Rollback Doomed Transaction
Figure 7:Rollback Doomed Transaction Figure 8:Rollback Doomed Transaction
Figure 8:Rollback Doomed Transaction