Transactions in SQL Server seems to be a difficult topic to grasp. This weekend I came across a blog-post where the poster showed a “solution” to the “The ROLLBACK TRANSACTION request has no corresponding BEGIN TRANSACTION” error we sometimes see when various stored procedures call each other. The solution (even though it masked out the error in question) did not get it quite right. So I thought I would make a post about the subject.
Nested Transactions in SQL Server and the Evil @@TRANCOUNT
In SQL Server we have the @@TRANCOUNT variable which gives us the number of transactions active in the session – or that’s at least what we might believe. Take this extremely simple code:
SET NOCOUNT ON
CREATE TABLE #t (col1 varchar(15))
PRINT @@TRANCOUNT
BEGIN TRAN
PRINT @@TRANCOUNT
INSERT INTO #t VALUES('HELLO')
BEGIN TRAN
PRINT @@TRANCOUNT
INSERT INTO #t VALUES('WORLD')
COMMIT
PRINT @@TRANCOUNT
COMMIT
PRINT @@TRANCOUNT
You should see something like this:
0
1
2
1
0
I.e. it seems like the transaction count is increasing for each BEGIN TRAN, and decrease with COMMIT. And if you were to SELECT * FROM #t you would see two rows returned. So far so good, so what is wrong with @@TRANCOUNT then? Well, let us change the code slightly (don’t forget to drop #t if you copy and paste this code):
SET NOCOUNT ON
CREATE TABLE #t (col1 varchar(15))
PRINT @@TRANCOUNT
BEGIN TRAN
PRINT @@TRANCOUNT
INSERT INTO #t VALUES('HELLO')
BEGIN TRAN
PRINT @@TRANCOUNT
INSERT INTO #t VALUES('WORLD')
COMMIT
PRINT @@TRANCOUNT
ROLLBACK
PRINT @@TRANCOUNT
If you now were to (don’t do it immediately) SELECT * FROM #t, how many rows would you get back – 0, 1, or 2? Seeing how the @@TRANCOUNT is increasing with every BEGIN TRAN and decreasing with COMMIT / ROLLBACK, it is understandable if your answer is 1:
- we start a transaction and insert a row
- we then start another transaction and insert a second row
- we call commit after the second insert (the inner transaction)
- finally we do a rollback, on the “outer” transaction
As we after the second BEGIN TRAN can see @@TRANCOUNT being 2, we could assume that the commit would commit the second insert. However, we all know what happens when we assume (now would be a good time to do the SELECT) ….
Right, the SELECT did not return any rows at all, so it is probably fair to say that we did not have multiple transactions, even though @@TRANCOUNT showed us more than one. So, then we might assume (keep in mind what I’ve said about assume) that the reason we rolled back was because ROLLBACK was the last statement. Let us switch the COMMIT on line 10 with the ROLLBACK on line 12 (we now have ROLLBACK on line 10 and COMMIT on line 12) and execute. WHOA – we got a big fat exception, what happened here? To answer that, let us look a bit closer at the main parts of transaction control in your code.
BEGIN TRAN, COMMIT and ROLLBACK
When you execute BEGIN TRAN in T-SQL, SQL will look around in the execution context of your session and see if there already exists a transactional context. If not, SQL will start a new transaction. If there is a transaction already, SQL will enlist in this transaction. However in both cases SQL will increase the @@TRANCOUNT variable.
Then, when you execute a COMMIT, SQL will not immediately commit the transaction but will decrease the transaction count with 1. If the transaction count has reached 0 due to the commit, a commit will take place. OK, so far so good, but this does not explain the error we received when switching the COMMIT and ROLLBACK statements, if it works as described, then we should have committed?
Ah, yes – however, a ROLLBACK not only decrements the transaction count – it sets it to 0 immediately, and as the transaction count is now 0, a rollback will happen. So in our second example we are seeing something similar to when we – in stored procs – are getting the ”The ROLLBACK TRANSACTION request has no corresponding BEGIN TRANSACTION” error.
Stored Procedures and Transactions
It is quite common to write procs something like so:
CREATE PROC sp2
AS
SET NOCOUNT ON
BEGIN TRAN
BEGIN TRY
-- do some stuff
-- then if all is OK we commit
COMMIT TRAN
RETURN 0;
END TRY
BEGIN CATCH
DECLARE @errMSg varchar(max);
SELECT @errMSg = ERROR_MESSAGE()
ROLLBACK TRAN
RETURN 999; --things have gone very wrong
END CATCH
Then we are having a similar proc, looking almost the same, but it, in addition, calls into sp2:
CREATE PROC sp1
AS
SET NOCOUNT ON
BEGIN TRAN
BEGIN TRY
-- do some stuff
-- do some more stuff by calling into sp2
EXEC sp2;
-- then if all is OK we commit
COMMIT TRAN
RETURN 0;
END TRY
BEGIN CATCH
DECLARE @errMSg varchar(max);
SELECT @errMSg = ERROR_MESSAGE()
ROLLBACK TRAN
RETURN 999; --things have gone very wrong
END CATCH
This is now when we will potentially see the error mentioned before. We call sp1, when sp1 is called there is no transactional context around, so SQL creates a new transaction. Then we go on to call sp2 from sp1. In the BEGIN TRAN call in sp2, there exists a transactional context, so SQL enlists us in that context.
If all now goes well and we call COMMIT in sp2, the commit causes the transaction count to be decreased to 1 – but no “real” commit happens. So when we subsequently calls COMMIT in sp1, we decrement the transaction count to 0, and we are committed.
In the case when things go wrong is sp2 and we call rollback, the transaction count is immediately set to 0, and a rollback happens. When we come back to sp1, SQL sees that we had a transaction in sp1, but there are no transactions around, and we will get the error discussed. If we then go on and do a rollback (as in our code) – we will get additional errors.
Solution
A solution to the problem is to use the “evil” @@TRANCOUNT, to see if there are any transactions around. If there aren’t any, we start a transaction. If there are a transaction already, we don’t do anything, and we let the existing transaction handle everything:
CREATE PROC sp2
AS
DECLARE @tranCount int = @@TRANCOUNT; --I'm using SQL2008 here
SET NOCOUNT ON
IF(@tranCount = 0) --no tx's around, we can start a new
BEGIN TRAN
BEGIN TRY
-- do some stuff
-- then if all is OK we commit
--if the variable @tranCount is 0,
-- we have started the tx ourselves, and can commit
IF(@tranCount = 0 AND XACT_STATE() = 1) --XACT_STATE - just to be on the safe side
COMMIT TRAN;
RETURN 0;
END TRY
BEGIN CATCH
DECLARE @errMSg varchar(max);
SELECT @errMSg = ERROR_MESSAGE()
--if the variable @tranCount is 0,
-- we have started the tx ourselves, and can rollback
IF(@tranCount = 0 AND XACT_STATE() <> 0) --XACT_STATE - just to be on the safe side
ROLLBACK TRAN;
--tell an eventual calling proc that things have gone wrong
--and the calling proc should rollback
RETURN 999;
END CATCH
Obviously the calling proc would have similar code to decide if to start a tran or not.
In the above scenario we let the “outer” proc handle all the transactional control. Sometimes you are in a situation where – if things go wrong in the “inner” proc (sp2 in our case) – you do not want to roll back everything done, but only what was done in the inner proc. For such a scenarion, you can use named savepoints:
CREATE PROC sp2
AS
DECLARE @tranCount int = @@TRANCOUNT; --I'm using SQL2008 here
SET NOCOUNT ON
IF(@tranCount = 0) --no tx's around, we can start a new
BEGIN TRAN
ELSE --we are already in a tx, take a savepoint here
SAVE TRANSACTION sp2 --this is just a name
BEGIN TRY
-- do some stuff
-- then if all is OK we commit
--if the variable @tranCount is 0,
-- we have started the tx ourselves, and can commit
IF(@tranCount = 0 AND XACT_STATE() = 1) --XACT_STATE - just to be on the safe side
COMMIT TRAN;
RETURN 0;
END TRY
BEGIN CATCH
DECLARE @errMSg varchar(max);
SELECT @errMSg = ERROR_MESSAGE()
--if the variable @tranCount is 0,
-- we have started the tx ourselves, and can rollback
IF(@tranCount = 0 AND XACT_STATE() != 0) --XACT_STATE - just to be on the safe side
ROLLBACK TRAN;
ELSE IF (@tranCount > 0 AND XACT_STATE != -1)
ROLLBACK TRANSACTION sp2 --we are rolling back to the save-point
--tell an eventual calling proc that things have gone wrong
--and let the calling proc decide what to do with its parts
RETURN 999;
END CATCH
Personally, I do not use named save-points that much as they cannot be used together with linked servers, and we – unfortunately – are using linked servers a lot.
A final note about named save-points; they are not the same thing as beginning / committing / rolling back a transaction with a name:
SET NOCOUNT ON
CREATE TABLE #t (col1 varchar(15))
BEGIN TRAN t1
INSERT INTO #t VALUES('HELLO')
ROLLBACK TRAN t1
Beginning a transaction with a name, is for most parts just a convenience. It has no effect on nesting (unless you use named save points), and SQL Server Books OnLine says this about naming of transactions:
“Naming multiple transactions in a series of nested transactions with a transaction name has little effect on the transaction. Only the first (outermost) transaction name is registered with the system. A rollback to any other name (other than a valid savepoint name) generates an error. None of the statements executed before the rollback is, in fact, rolled back at the time this error occurs. The statements are rolled back only when the outer transaction is rolled back”.
If you have questions, observations etc., please feel free to leave me a comment, or drop me an email.
![]()
 . In my list I also mentioned finally blocks. From what I can see that has not been implemented either, BUT something else has…
. In my list I also mentioned finally blocks. From what I can see that has not been implemented either, BUT something else has…


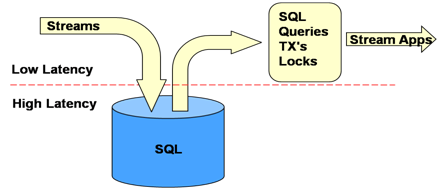 Figure 1:RDBMS’s Handling Stream Data
Figure 1:RDBMS’s Handling Stream Data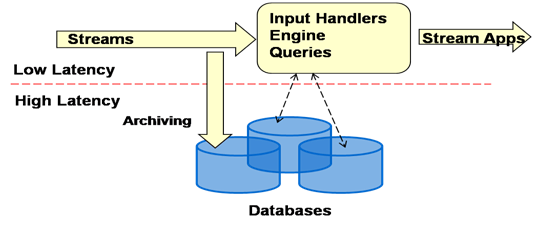 Figure 2:General Overview of DSMS
Figure 2:General Overview of DSMS